Fundamental data structures: Linked List
This post covers an intermediate system/algorithm designer to a high-throughput data system using linked lists. For the same of brevity code examples are kept brief.
Motivation
The theory behind one of the most fundamental data structures linked list is by itself fascinating but to give a motivation let’s start with a real-life example. Recently I’ve had to deal with a lot of sensor data. By lot I mean 40Msps of 32bit data which is around 160MBps. Using memcpy on all of it is simply not a viable option because memory oprations are known to be slow and the system is already busy with the data stream and we haven’t yet even talked about the application layer. Since we don’t want to waste cpu time copying this data stream and we still want to do something useful with the data what options do we have?
The first list implementation I used was the ArrayList in Java. In Python a simple list is created with []. New variables can be added to the list with .append(). These are good implementations to work with when learning basic data structure interfaces. They are good abstractions since they can be used without any knowledge of underlying implementation and they have readily available connections to algorithms like sorting and shuffling.
A benefitial standpoint for an argument over design is to be able to analyze the implementations and argue why it is best suitable for a given task. One might settle for a working implementation in this case a list structure because it “works out of the box” and “gets the job done”. But to be able to argue over design choises is crucial in algorithm analysis and solution evaluation. We’ll come back to this analysis at the end of this post.
Let’s dive into a little C code. We’ll look at different design choises in low-level data structure implementations and possible design patterns that emerge.
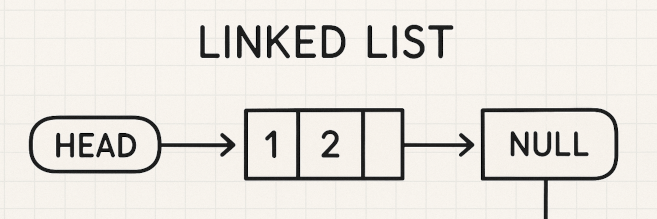
Data structures
To understand data structures deeply I would state the best way to learn is to look into low level programming concepts like instruction set architectures, CPU core architecture, memory layout, data types and pointers since they all common factors in all computing. At the core linked list is a collections of nodes that point to the next node. This enables the list to be stored in scattered memory locations. This is in contrast to array where data is stored in a single block of continuous memory.
typedef struct node {
uint32_t payload;
node* next;
} node;
typedef struct linked_list_h {
node* first_element;
} linked_list_h;
In a struct all elements are memory aligned by the compiler. The node has a pointer to the next node in the list in a nested structure. This is a completely fine definition in C. The last element is null terminated so we know we have reached the end of the list. To access the nth element in the list we simply count pointer accesses until we are at the nth entry of the list. Note that we could eliminate out-of-bound index access by creating a size variable that is incremented and decremented when adding or removing elements to the linked list.
One thing to note is that C does not enforce coding paradigmas like object oriented programming languages. This means the programmer is responsible for using different design patterns. Remember nothing is taken for granted in C.
For a system to access and use the linked list we need to initiate a handle with a fixed pointer to the first element of the list. This type of linekd list is called an intrusive linked list. The word intrusive means that the node pointers and the payload are embedded to the same data strcuture. To finish this implementation we would then design an API for the user. While this implementation is valid approach we may want to include the same payloads in multiple lists. Using this implementation would mean having multiple copies of a single payload in the memory.
If we know we have multiple lists that include the same items we can use another approach.
typedef struct node {
node* next;
void* payload;
}
The void* pointer is used to note that the data can be anything. This is not couraged in practise but it notes the payload can be in theory any data type.
This way the payload exists somewhere in the memory and it can be included to several lists. As a trade-off it is now the programmers resposibility to make sure the payload is freed correctly.
We can place these nodes in a flat memory map region. The region is managed separately and has it’s size limits etc. It can be placed in a shared memory location. These are just some ideas to prove what they can be used for. Isolating the nodes like this to a single control block makes it likely the whole region fits to a cpu cache register. This again makes it possible to iterate the list in blazing fast speed! Note that the payload still need to be fetched from another region is not affected by cache hits.
Now if we think back didn’t we just state a while back that linked lists are good for the fact that they can be resized? Doesn’t the control block approach eliminate this feature? In one way yes.
Optimization and linked lists
To give a common example we can malloc memory regions from the heap but the system memory is still finite. A proper approach to control block logic would be to initiate a bigger memory region chunk on the stack and divide the region to node sized slots using a free list. This is a list of nodes that can be used to store a single node. When a new node is created it is removed from the free list and placed to an occupied list. Adding and removing elements updates the free and occupied lists accordingly. Since the linked list is allocated in the stack no syscalls are made which improves performance.
In practise: A high-troughput data system
I want to discuss the design I settled with in the high throughput data system I talked about at the start of this post. Since we don’t want to do any unnecessary copies of the data with memcpy a bigger ring buffer seemed like the best choise. Note that a ring buffer can be implemented with either an array or a linked list. An array was chosen because of the uniformly sampled data and ease of access for all indices (ref. base pointer).
A 10GB buffer was chosen. This ensures the buffer holds data history of 62.5 seconds which is plenty of time for readers to operate on the data. The buffer wraps around and overwrites the old data thus old data does not need to be manually erased. In the buffer we have a _write_index and a _read_index that point indices in the buffer where _write_index is the next writable address and _read_index points to the last unread address.
Data is accessed using pointers. This means we have a get_next_write_buffer() and get_next_read_buffer() that return a pointer to the indices. By assumption only one writer operates on the buffer. By design the buffer data should no be modified and is thus read only. Since I know that not all of the data is of interest as it might be just noise a seekable reader was chosen. Seekable means that the reader can traverse the ring buffer. Only every nth entry is read for noise check. If there happens to be something else besides noise in the data then the reader looks in the adjecent buffers as well.
You might have noticed, yes, the reader can be configured to skip buffers. After all processing the whole data stream is very expensive.
This results in sliced time series data where noise regions are discarded. Given a timestamp for recording start time and the data as payload the data is pushed to a fifo (first-in-first-out) queue linked list for later processing.
Final notes
In the before mentioned data system throughput is the most important requirement. Only a single linked list was used for the later fifo queue. For the first implementation of the system I did use a linked list that used a heap allocated memory region but it resulted in a lot of data overflows in the recording device. Operating solely on pointers makes the data writing and reading very fast thus nearly zero overflows. The system can be scaled vertically by using several reader/worker threads that copy data from the raw data buffer.
In the end hard real-time performance is not that critical in this system. This solution is itself pleasingly fast and provides flexibility to the upper stacks but it not as fast as possible. A yet more real-time system can be thought of as an exercise.
System design like this encourages to think deeply about data structures and see the whole system as a collection of different components. I also concidered double or n-buffering. Having a single writer and reader had the possibility to set a roughly constant time delay between the reader and writer.
Hope you learned something new here. Have a happy day!